Az itt bemutatott új matematikai módszer tetszőleges diszkrét mintázat (belső) információtartalmára ad pontosabb becslést Shannon eredeti függvényére építve. A módszert különböző adatsorokon teszteljük és az eredményeket összehasonlítjuk más módszerek eredményeivel.
Abstract: Ebben a tanulmányban egy új többléptékű információtartalom számítási módszert mutatunk be, amely a Shannon-entrópián alapul. A Claude E. Shannon által leírt, és az elemek valószínűségének logaritmusán alapuló eredeti módszer felső korlátot ad a diszkrét mintázatok információtartalmára, de sok esetben (például ismétlődést tartalmazó mintázatok esetén) pontatlan, és nem tükrözi a mintázat valódi információtartalmát. Az itt bemutatott új matematikai módszer tetszőleges diszkrét mintázat (belső) információtartalmára ad pontosabb becslést Shannon eredeti függvényére építve. A módszert különböző adatsorokon teszteljük és az eredményeket összehasonlítjuk más módszerek eredményeivel.
1 Bevezetés
Hagyományosan Shannon információelméletét [13] használták a mintázatok információtartalmának mérésére. A Shannon-információ Claude E. Shannon meghatározása szerint a bizonytalanság vagy meglepetés mértéke, amely egy adott kimenetelhez kapcsolódik a lehetséges kimenetelek halmazában. A Shannon-entrópia, amely a Shannon-információ várható értéke, egy diszkrét mintázat vagy üzenet átlagos információtartalmának számszerűsítésére szolgál. Alapfogalomként szolgál az információelméletben, és széles körben használják kommunikációs rendszerekben és adattömörítésben.
Bizonyos helyzetekben, például ismétlődő mintázatok esetén Shannon eredeti információmérési módszere nem ad kellően pontos eredményt, mert nem veszi figyelembe a mintázatok szerkezetét, csak azok bizonyos statisztikai jellemzőit nézi. Ennek a problémának a megoldására ez a cikk egy új, többléptékű információtartalom számítási módszert mutat be, amely Shannon eredeti elvein alapul. Módszerünk a számítási megközelítés finomításával pontosabb becslést kínál a diszkrét mintázatok belső információtartalmára, függetlenül azok természetétől.
Számos más módszer is létezik a mintázatok információtartalmának mérésére, mint például a Kolmogorov-komplexitás [8], a véletlenszerűség [9] és a tömörítési komplexitás. E módszerek közös tulajdonsága, hogy valamennyien alkalmasak a mintázatok információtartalmának bizonyos pontosságú meghatározására, megértésére, így megfelelő összehasonlítási alapot adnak az újabb módszerek ellenőrzéséhez.
Új módszerünk hatékonyságának ellenőrzésére különféle adatkészletekre alkalmazzuk, és összehasonlítjuk tömörítési algoritmusokkal. Az eredmények azt mutatják, hogy az általunk javasolt Shannon információkon alapuló módszerünk jól közelíti a más módszerekkel mért eredményeket, miközben teljesen más megközelítést alkalmaz.
2 Mintázat
Jelen tanulmányban diszkrét mintázatok belső mennyiségi információtartalmának számításával foglalkozunk. Az információtartalom számítása szempontjából lényegtelen, hogy a mérés tárgya milyen jellegű. Az információtartalmát számíthatjuk eseményeknek, jelforrásokból származó jeleknek, rendszerek állapotának, vagy adatsoroknak, mivel ezek modelljei (véges pontossággal) mind reprezentálhatók diszkrét mintázatként. Egy térbeli mintázaton végighaladva időbeli mintázatot kapunk és fordítva. Ezért nem teszünk különbséget térbeli és időbeli mintázat között. Az alapvető jelölések legyenek a következők.
Az halmazból előállítható véges sorozatok halmazát jelölje :
Nevezzük mintázatnak az véges sorozatot:
Az sorozat hosszát jelölje:
Az sorozat értékkészletének halmazát jelölje:
Jelöljük -el az előfordulásainak számát az sorozatban:
Az mintázat bármely elemének relatív gyakorisága legyen:
Az mintázatok konkatenációját jelölje:
3 Információtartalom
Az információtartalom intuitív módon értelmezhető, ha csak az értelmezhető információtartalmat vizsgáljuk [1]. Ebben a tanulmányban a teljes belső információtartalom mennyiségét vizsgáljuk anélkül, hogy értelmeznénk, vagy a kontextust figyelembe vennénk.
Egy mintázat információtartalmát többek között jellemezhetjük a mintázat egyes elemeinek valószínűtlenségével (Shannon-információ [13]), a mintázat legtömörebb leírásának hosszával (Kolmogorov-komplexitás [8]), vagy a mintázat véletlenszerűségének mértékével [9].
Alapvető különbség Shannon és Kolmogorov nézőpontja között, hogy Shannon csak a mintázatot létrehozó véletlenszerű információforrás valószínűségi jellemzőit tekintette, figyelmen kívül hagyva magát a mintázatot. Ezzel szemben Kolmogorov csak magára a mintázatra koncentrált[5]. Kolmogorov és Chaitin definíciójukban azt a mintázatot nevezték (pontatlanul fogalmazva) véletlenszerűnek, amelynek maximális az információtartalma[10].
Az információ, a komplexitás és a véletlenszerűség annyira hasonló tulajdonságokkal rendelkeznek, hogy jogosan feltételezhetjük: lényegében ugyanazt a dolgot közelítik különböző módszerekkel. Elegendő, ha arra gondolunk, hogy az azonos elemekből álló mintázatnak a Shannon-információja, a Kolmogorov-komplexitása és a véletlenszerűsége egyaránt minimális, míg a valódi véletlen mintázat esetén mindhárom érték maximális.
Az entrópia és az információ fogalmát gyakran keverik[3], ezért fontos megemlíteni, hogy az entrópia nem más, mint az elemenkénti átlagos információtartalom, más néven információsűrűség.
Intuitív módon megközelítve az információmennyiség olyan függvény, amelyre teljesülnek az alábbi feltételek:
- A nulla hosszúságú vagy azonos elemekből álló mintázat információtartalma nulla.
- Az ismétlődő szakaszokból álló mintázat információtartalma (közel) azonos az ismétlődő szakasz információtartalmával.
- Egy mintázatnak és a tükörképének azonos az információtartalma.
- Diszjunkt értékkészletű mintázatok információtartalmának összege kisebb, mint az összefűzött mintázat információtartalma.
- A valódi véletlenszerű mintázatok információtartalma közel maximális.
Az információtartalom legyen az függvény, amely bármely tetszőleges mintázathoz egy nemnegatív valós számot rendel:
Továbbá teljesülnek az alábbi feltételek:
- esetén, ahol valódi véletlen mintázat.
Mivel bármely mintázat leírható tovább nem bontható bináris alakban, ezért az információtartalom mértékegysége legyen a bit.
Belátható, hogy bármely mintázat esetén, ha és , akkor az maximális információtartalma:
Vagyis bármely mintázatra. Bináris mintázat esetén , a mintázat hossza, ami azt jelenti, hogy maximum bit információ (döntés) szükséges a mintázat leírásához.
Ha ismerjük a maximális információtartalmat, akkor kiszámítható a relatív információtartalom:
4 Shannon-információ
A Kolmogorov-komplexitás elméletben ugyan jobb közelítést adna a mintázatok információtartalmára, de bizonyítottan nem kiszámítható[5], ellentétben a Shannon-információval [13], amely hatékonyan számítható, de kevésbé jól közelíti a tényleges információtartalmat. A Shannon-információ a mintázat információtartalmát a mintázat elemeinek a várható előfordulási valószínűsége (relatív gyakorisága) alapján számítja.
Egy tetszőleges mintázat Shannon-információja:
Mivel a mintázat elemeinek a relatív gyakorisága (várható előfordulása) csak egy statisztikai jellemzője a mintázatnak (a sok közül), és nem veszi figyelembe az elemek sorrendjét, ezért a Shannon-információ gyakran nagyon pontatlan becslést ad az információtartalomra. A Shannon-információ értéke megegyezik minden olyan azonos hosszúságú mintázat esetén amelyek elemei azonos relatív gyakoriságúak. Ha , és akkor teljesül, hogy:
A Shannon-információ figyelmen kívül hagyja a mintázatok különböző léptékű struktúráját, az abban kódolt törvényszerűségeket, így az ismétlődő szakaszokból álló mintázatok információtartalmát is túlbecsüli.
A probléma egy egyszerű példával szemléltethető. Számoljuk ki a következő három mintázat Shannon-entrópiáját:
Az értékkészlet mindhárom esetben , az egyes elemek valószínűsége és , a Shannon-entrópia pedig , pedig nyilvánvaló, hogy az adatsorok információtartalma jelentős mértékben eltér egymástól. Az adatsor információtartalma a véletlenszerűségéből adódóan közel 16 bit, míg a másik két adatsor információtartalma jóval kisebb, hiszen ismétlődő szakaszokat tartalmaznak. Az adatsorban például a 2 bites szakasz ismétlődik, ami azt jelenti, hogy az információtartalma a 2 bithez áll közelebb.
A probléma az, hogy fenti példában az adatsorokat elemi szinten vizsgáljuk, és a Shannon-entrópiafüggvényünk nem vesz tudomást az adatsor nagyobb léptékű szerkezetéről, mint például az 1 jelnél hosszabb, ismétlődő szakaszok jelenléte. Ezért kézenfekvő az olyan módszerek kidolgozása, amely a Shannon-entrópián alapulnak, de az adatsorokat a felbontás teljes spektrumában, a teljes frekvenciatartományban elemzik, és így pontosabb közelítést adnak az adatsor információtartalmára. Számtalan ilyen megoldást publikáltak már, amelyek például a [2] és a [6] cikkekben olvashatóak. Jelen cikk további módszereket mutat be.
5 SSM-információ
5.1 Shannon-információspektrum
Legyen az mintázat hosszúságú szakaszonkénti partícionálása, ha :
A következő sorozatot nevezzük az mintázat Shannon-információspektrumának (SP, Shannon Information Spectrum):
Az sorozatokból kihagyjuk az -nél rövidebb (csonka) partíciókat, azokat, amelyek rövidebbek -nél. Az esetekben az lenne, ezért ezeket szintén kihagyjuk a spektrumból.
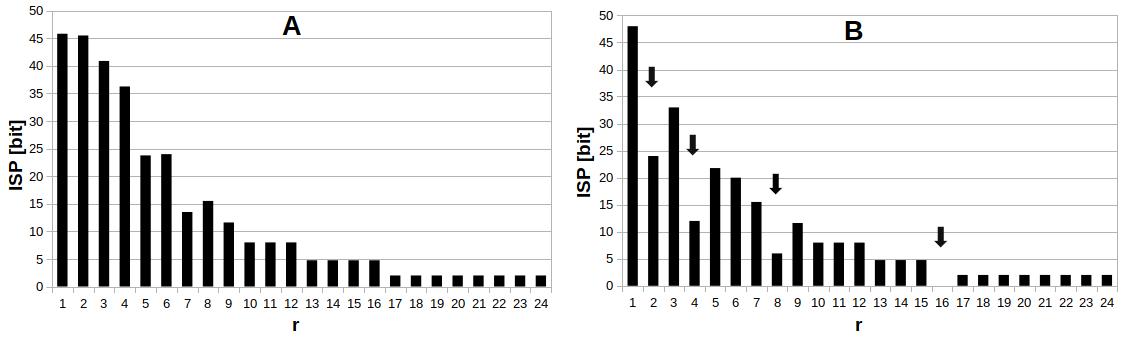
1. Ábra. Az diagramon az véletlenszerű mintázat Shannon-információspektruma látható, a ábrán pedig az ismétlődő mintázaté (I. függelék). Látható, hogy a esetben bizonyos frekvenciákon alacsonyabb érték jelenik meg.
5.2 Maximális Shannon-információspektrum
Az Shannon-információspektrum a véletlenszerű adatsorok esetén lesz maximális, amit nevezzünk maximális Shannon-információspektrumnak (SMS, Shannon Maximum Information Spectrum) és a következő képlettel számítjuk:
Ha elég kicsi, akkor az sorozatban nagy valószínűséggel minden lehetséges érték szerepel, ezért a mért információmennyiség közelítőleg meg fog egyezni a mintázat maximális lehetséges információtartalmával, azaz ha kicsi, akkor .
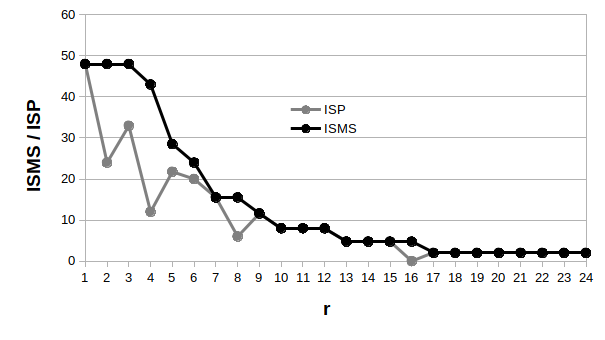
2. Ábra. A maximális Shannon-információspektrum (ISMS) és az ismétlődő mintázat Shannon-információspektrumának (ISP) az összehasonlítása.
5.3 Normalizált Shannon-információspektrum
Ha arra vagyunk kíváncsiak, hogy a maximális értékhez képest relatíve mennyinek látszik az információtartalom az egyes felbontásokban, akkor a spektrumot a maximális spektrummal normalizálhatjuk a tartományba. A normalizált Shannon-információspektrum (SNS, Shannon Normalized Information Spectrum) legyen a következő sorozat:
Abban az esetben, ha a normalizált érték lenne, az azt jelenti, hogy ismétlődő partíciókról van szó. Ebben az esetben az információtartalom az ismétlődő partíció információtartalma lesz, és az elemi felbontás egy elemének átlagos Shannon-entrópiáját megszorozzuk a partíció hosszával: .
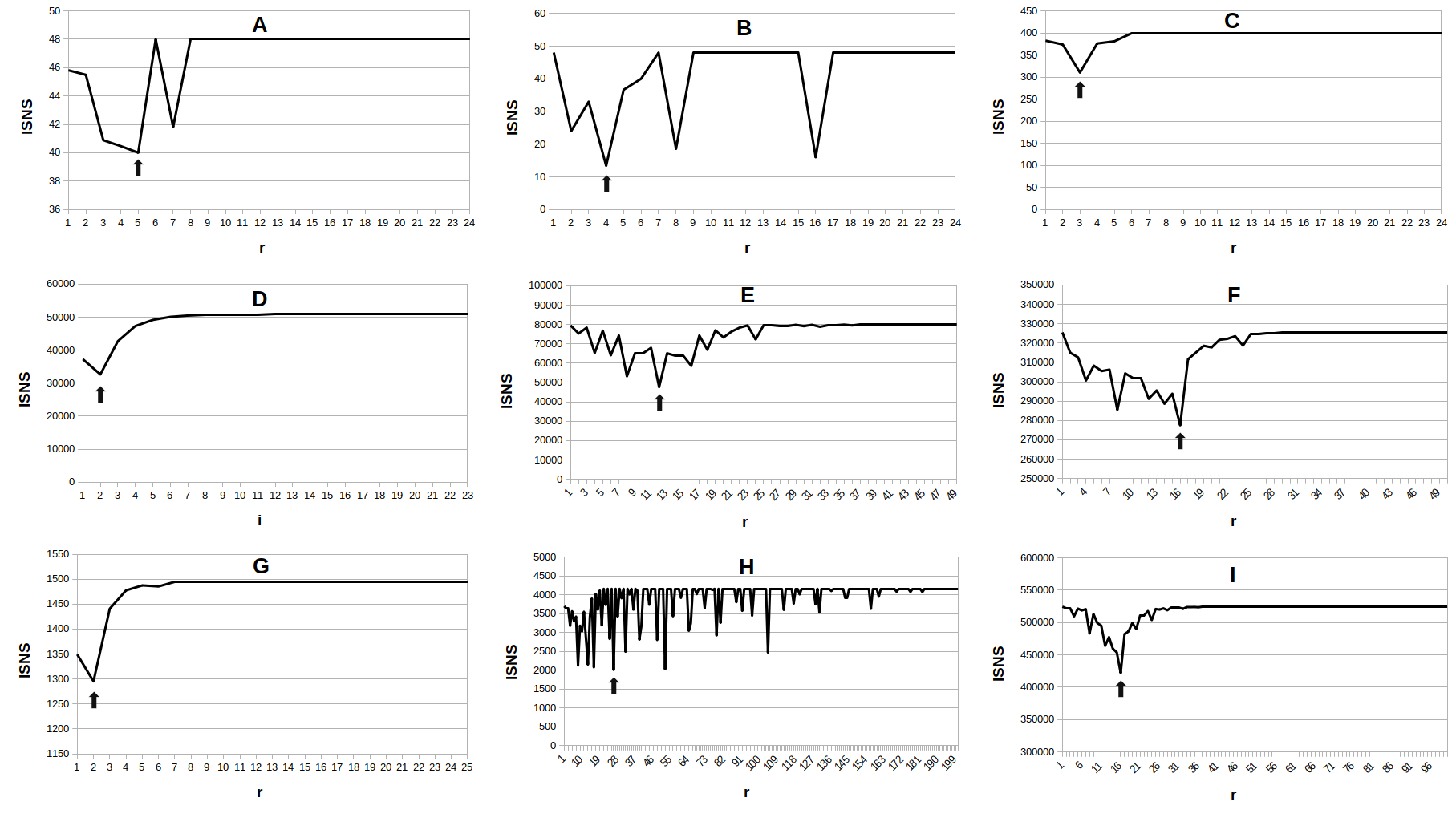
3. Ábra. Nagyon különböző forrásokból származó mintázatok normalizált Shannon-információspektrumainak összehasonlítása. Látszik, hogy a különböző mintázatoknak mennyire eltérő a spektruma, de a legtöbb esetben van olyan felbontás, ahol határozott minimumot mutat az információtartalom. A minimumokat nyíllal jelöltük. A: random bináris mintázat, B: bináris mintázat ismétlődő szakaszokkal, C: DNS-szakasz, D: angol szöveg, E: ECG-jel, F: beszédet tartalmazó hangfelvétel, G: a napfoltok számának alakulása 1700-2021 között, H: szeizmogram, I: Lena fotója.
5.4 SSM-információ
Tudjuk, hogy a Shannon-információ minden esetben felső becslést ad, ezért a normalizált spektrumból akkor kapjuk meg az információtartalom legpontosabb közelítését, ha a minimumát vesszük. A normalizált spektrumból számított információtartalmat nevezzük SSM-információnak (Shannon Spectrum Minimum Information):
Különböző mintázatok (I. függelék) Shannon-információja, SSM-információja és tömörítési komplexitása bit-ben kifejezve:
|
Mintázat
|
Forrás
|
||||||
|
X
|
Véletlenszerű bináris mintázat.
|
48
|
46
|
40
|
|||
|
X
|
Ismétlődő bináris mintázat.
|
48
|
48
|
2
|
|||
|
X
|
Ismétlődő bináris mintázat.
|
48
|
48
|
13
|
|||
|
X
|
Ismétlődő szövegrész.
|
362
|
343
|
58
|
|||
|
X
|
Ismétlődő szövegrész egy karakternyi hibával.
|
374
|
347
|
116
|
|||
|
X
|
Véletlenszerű DNS mintázat.
|
471
|
422
|
409
|
|||
|
X
|
COVID vírus DNS-szakasza.
|
471
|
405
|
388
|
|||
|
X
|
Véletlenszerű karaktersorozat (0-9, a-z, A-Z).
|
1209
|
1174
|
1174
|
|||
|
X
|
Angol szöveg (James Herriot's Cat Stories).
|
1104
|
971
|
971
|
|||
|
X
|
Naptevékenység 1700-2021 között (A-Z).
|
1495
|
1349
|
1295
|
|||
|
X
|
Isaac Asimov: True love.
|
50901
|
37266
|
32649
|
30904
|
29968
|
25248
|
|
X
|
Bináris ECG szignál.
|
80000
|
79491
|
47646
|
52320
|
41032
|
36968
|
|
X
|
Bináris földmozgás adat.
|
313664
|
312320
|
171546
|
83920
|
66064
|
45824
|
|
X
|
Beszéd hangfelvétel.
|
325472
|
325342
|
277489
|
286760
|
257856
|
251408
|
|
X
|
Lena képe.
|
524288
|
524216
|
422085
|
443096
|
371360
|
337408
|
Különböző mintázatok (I. függelék) relatív Shannon-információja, SSM-információja és tömörítési komplexitása a maximális információhoz viszonyítva:
|
Mintázat
|
Forrás
|
%
|
%
|
%
|
%
|
%
|
|
X
|
Isaac Asimov: True love.
|
73
|
64
|
61
|
59
|
50
|
|
X
|
Bináris ECG szignál.
|
99
|
60
|
65
|
51
|
46
|
|
X
|
Bináris földmozgás adat.
|
100
|
55
|
27
|
21
|
15
|
|
X
|
Beszéd hangfelvétel.
|
100
|
85
|
88
|
79
|
77
|
|
X
|
Lena képe.
|
100
|
81
|
85
|
71
|
64
|
A táblázatból látszik, hogy az SSM-információ hasonló eredményeket ad, mint a tömörítési algoritmusok. Általánosságban igaz, hogy minél nagyobb számítási igényű egy tömörítési vagy információ-mérő eljárás, annál jobban közelíti a Kolmogorov-komplexitást. A vizsgált példákban az SSM-információ eredményei általában a ZIP és a 7Z eredményei között helyezkednek el, így az SSM-információ számítási komplexitásának is hasonlónak kell lennie a ZIP és a 7Z számítási komplexitásához.
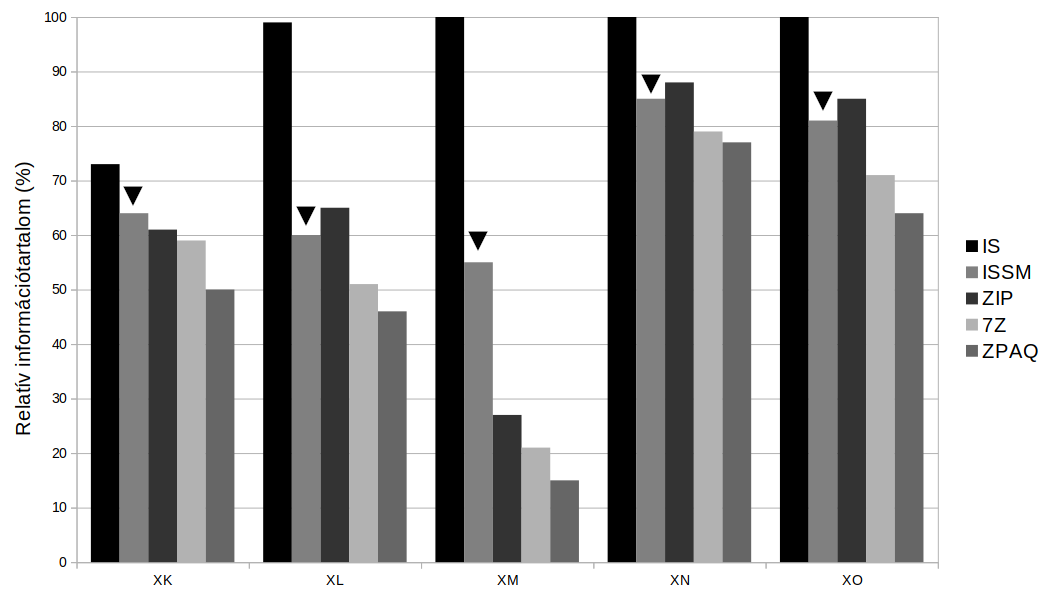
3. Ábra. A különböző információmérési módszerek eredményeinek összehasonlítása.
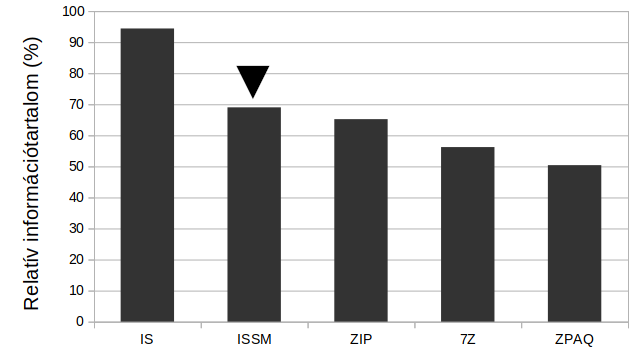
4. Ábra. A különböző információmérési módszerek átlagos eredményeinek összehasonlítása.
5.5 Számítási komplexitás összehasonlítása
Ha nem ismerjük a jelsorozat jelkészletét, az első lépés, hogy meghatározzuk a jelsorozatban előforduló jelek számát, ami asszimptotikus komplexitású.
A Shannon-információ meghatározása két lépésből áll. Az első lépésben meghatározzuk a jelek gyakoriságát, ami komplexitású, második lépésben pedig összegezzük az egyes jelek entrópiáját, így a Shannon-információ összkomplexitása .
A tömörítési komplexitás számítására használt ZIP, 7Z és ZPAQ algoritmusok esetén a komplexitás általában és között van, de a ZPAQ esetén lehet ennél nagyobb [7] [12] [11].
Az SSM-információ esetén az első lépés szintén a jelek gyakoriságának meghatározása, ami komplexitású. A második lépésben a Shannon-információspektrum kiszámítása komplexitású, végül a spektrum minimuma meghatározható komplexitással. Az SSM-információ kiszámításának komplexitása legrosszabb esetben , ami a tömörítési algoritmusokéval azonos.
5.6 Ismert problémák
Minden információmennyiség számítási módszernek vannak pontatlanságai. Az SSM-információ egyik problémája, hogy ha egy ismétlődő mintázatban nem tökéletes az ismétlődés, az SSM-információ értéke nagyobb a vártnál, amint az alábbi példa is mutatja.
|
[bit]
|
|
|
123456789 123456789 123456789
|
29
|
|
223456789 123456789 123456789
|
50
|
6 Konklúzió
Az SSM információ a tömörítési komplexitásokkal összemérhető pontossággal képes meghatározni a mintázatok információtartalmát, ugyanakkor egyszerű. Az itt bemutatott információspektrum egy hasznos vizuális eszközt biztosít a mintázatok információszerkezetének tanulányozására.
References
- , "Fast Autocorrelated Context Models for Data Compression", (2013).
- , Complexity of Algorithms (Boston University, 2020).
- , "Entropy and Information Theory: Uses and Misuses", Entropy (2019).
- , "Facticity as the amount of self-descriptive information in a data set", (2012).
- , "Fast BWT in small space by blockwise suffix sorting", Theoretical Computer Science (2007).
- , "On tables of random numbers", Mathematical Reviews (1963).
- , "Information and Complexity (How To Measure Them?)", The Emergence of Complexity in Mathematics, Physics, Chemistry and Biology, Pontifical Academy of Sciences (1996).
- , "The Multiscale Entropy Algorithm and Its Variants: A Review", Entropy (2015).
- , "Multiscale Information Theory and the Marginal Utility of Information", Entropy (2017).
- , "PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals.", Circulation (2000).
- , "A Lempel-Ziv-style Compression Method for Repetitive Texts", (2017).
- , "Shannon Information and Kolmogorov Complexity", CoRR (2004).
- , "A Mathematical Theory of Communication", Bell System Technical Journal (1948).
- , Introduction to Systems Philosophy (Routledge, 1972).
- , "What is Shannon information?", Synthese (2015).
Függelék
I. Példa mintázatok
|
Jelölés
|
Mintázat vagy annak részlete
|
Hossz
|
Magyarázat
|
|
001101101010111001110010001001000100001000010000
|
48 bit
|
Véletlenszerű bináris mintázat.
|
|
|
101010101010101010101010101010101010101010101010
|
48 bit
|
Ismétlődő bináris mintázat.
|
|
|
111111110000000011111111000000001111111100000000
|
48 bit
|
Ismétlődő bináris mintázat.
|
|
|
The sky is blue. The sky is blue. The sky is blue.
|
101 karakter
|
Ismétlődő szövegrész.
|
|
|
The sky is blue. The sky is blue. The sky is blue.
|
|||
|
The sky is blue. The sky is blue. The sky is blue.
|
101 karakter
|
Ismétlődő szövegrész egy karakternyi hibával.
|
|
|
The sky is blue. The sky is glue. The sky is blue.
|
|||
|
cagtttctagctatattagcgggcacgactccactgcgcctatgcggaag
|
200 karakter
|
Véletlenszerű DNS mintázat.
|
|
|
cttgatcaaattttgaccagatcttaggtaacctgaacaagtcagttcgt
|
|||
|
aggcgtcgattggccgacgggtgcgaagaaaaaagtgatcgttgtccaac
|
|||
|
atctctagtacccaccgttgtgatgtacgttatacggacacgagcatatt
|
|||
|
cggcagtgaggacaatcagacaactactattcaaacaattgttgaggttc
|
200 karakter
|
COVID vírus DNS-szakasza.
|
|
|
aacctcaattagagatggaacttacaccagttgttcagactattgaagtg
|
|||
|
aatagttttagtggttatttaaaacttactgacaatgtatacattaaaaa
|
|||
|
tgcagacattgtggaagaagctaaaaaggtaaaaccaacagtggttgtta
|
|||
|
EK8Pi5sv2npTfzoaMNp87QtT5kbIUQkTJzHwICCstSmg4aksHT
|
200 karakter
|
Véletlenszerű karaktersorozat (0-9, a-z, A-Z).
|
|
|
MwztgHFg3j8AoIobN3FycCLidGeyROiNyG5itB9kxyez1LZjFF
|
|||
|
HIBjipE7hidZyiJmilXM0mwnxzlzWSfQ0xP1OuFpWosMwS1cjY
|
|||
|
t4nyv4ONx1FceWkAf8SdvDGZVzeVzq2EmOqRF6Im2iudcYRswj
|
|||
|
I think it was the beginning of Mrs. Bond's
|
221 karakter
|
Angol szöveg (James Herriot's Cat Stories)
|
|
|
unquestioning faith in me when she saw me
|
|||
|
quickly enveloping the cat till all you could
|
|||
|
see of him was a small black and white head
|
|||
|
protruding from an immovable cocoon of cloth.
|
|||
|
ABCDFIEDBBAAAABEHJJGEEDBDGMSPLHFBACFKMRPLGDCA[...]
|
321 karakter
|
Naptevékenység 1700-2021 között (A-Z).
|
|
|
My name is Joe. That is what my colleague,
|
8391 karakter
|
Isaac Asimov: True love.
|
|
|
Milton Davidson, calls me. He is a programmer and
|
|||
|
I am a computer program. [...]
|
|||
|
1011000100110011101110111011001100110011[...]
|
80000 bit
|
Bináris ECG szignál [4].
|
|
|
110000101000000011000010100000001100001010000[...]
|
313664 bit
|
Bináris földmozgás adat.
|
|
|
0101001001001001010001100100011011100100[...]
|
325472 bit
|
Beszéd hangfelvétel.
|
|
|
1010001010100001101000001010001010100011[...]
|
524288 bit
|
Lena fotója (256x256 pixel, szürkeárnyalatos).
|
Szerző:
Pőcze Zsolt
Volgyerdo Nonprofit Kft., Nagybakonak, HUN, 2023








