A biológia és az informatika egyik legnagyobb közös területe az idegsejthálózatok kutatása és mesterséges idegsejthálózatok készítése. A mesterséges intelligencia korunk egyik legfontosabb vívmánya, ezért cégünk is komoly hangsúlyt fektet a kutatására.
1. A neurális hálók típusai
Az általunk fejlesztett rendszerben a következő neurális hálózattípusokat különböztetjük meg:
-
Neurális háló (Network)
- Általános neurális háló (gráf alapú)
-
Réteges neurális háló (tenzor alapú)
- Teljesen kapcsolt neurális háló
- Konvolúciós neurális háló
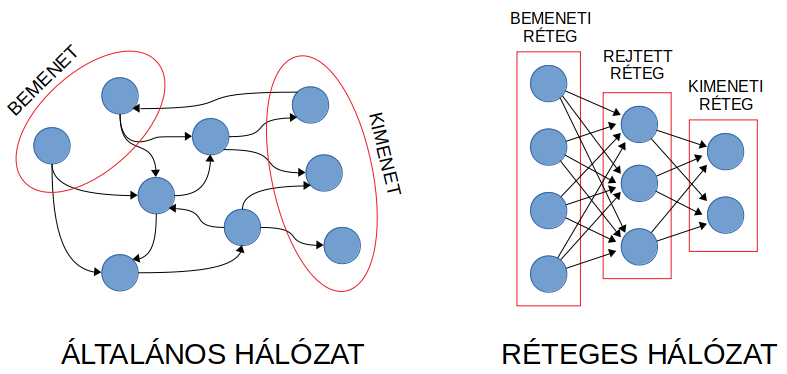
A gráf alapú általános (visszacsatolt) és a tenzor alapú réteges (egyirányú) neurális hálók felépítésének összehasonlítása:
2. A teljesen kapcsolt neurális háló
Teljesen kapcsolt esetben a háló szomszédos rétegeiben mindegyik neuron össze van kapcsolva a szomszédos réteg minden neuronjával. Ez jó, mert egészen bonyolult feladatokra is képes, viszont nagy az erőforrásigénye.
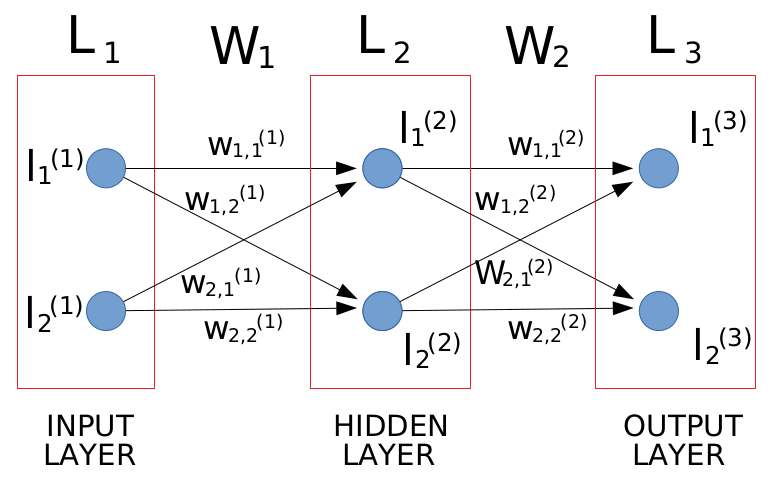
2.1. A teljesen kapcsolt neurális háló elemei
A háló k db. n dimenziós rétegből (layer) és k-1 db. 2n dimenziós súlytenzorból áll, amely a szomszédos rétegek közötti súlyokat tárolják. A rétegek neuronjainak állapotát n dimenziós tenzorok tárolják:
- L1, ..., Lk: a rétegek neuronjainak állapotát tároló, d1(i), d1(i), .... , dn(i) méretű, n dimenziós tenzorok (i = 1, ..., k)
- W1, ..., Wk-1: a rétegek közötti súlyokat tároló d1(i), d1(i), .... , dn(i), dn+1(i), dn+2(i), .... , d2n(i) méretű, 2n dimenziós tezorok (i = 1, ..., k-1)
A zárójelbe tett szám a réteg sorszámát jelenti.
2.2. A teljesen kapcsolt neurális háló működése
2.2.1. Előreterjesztés
Az előreterjesztés a normál működés, amikor a bemenet alapján a háló kimenetet képez.
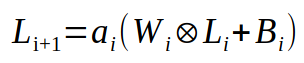
Jelmagyarázat:
- Li: i-dik réteg állapot tenzora
- ai: i-dik réteg aktivációs függvénye
- Wi: i-dik réteg súlytenzora
- Bi: i-dik réteg erősítési tényező tenzora
- ⊗: tenzor szorzás
Példa az egy dimenziós esetre, ahol a rétegek állapottenzorai 2 hosszúságú vektorok, a súlytényezők pedig 2x2-es mátrixként vannak ábrázolva:
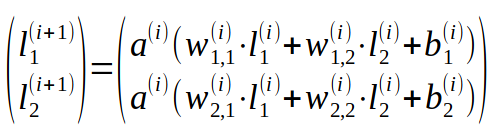
Az ábra az (i) és az (i+1) réteg közötti kapcsolatot mutatja, hogy hogyan kapjuk meg az egyik réteg értékeiből a másik réteg értékeit.
2.2.2. Hibavisszaterjesztés
A hibavisszaterjesztés folyamata, az elvárt kimenet megtanítása a hálóval.
Általános egyenletrendszer:

Egyenletrendszer a gyakorlatban használt jelöléssel:

Jelmagyarázat:
- L: a hálózat rétegszáma
- W(i): az i sorszámú rétegköz súlytenzora
- W*(i): az i sorszámú rétegköz új súlytenzora a hibavisszaterjesztés után
- B(i): az i sorszámú rétegköz erősítési tényező tenzora
- B*(i): az i sorszámú rétegköz új erősítési tényező tenzora a hibavisszaterjesztés után
- X(i): az i. réteg állapottenzora
- a'(): aktivációs függvény deriváltja
- E: az utolsó réteg hibatenzora (elvárt kimenet - kimenet különbsége)
- r: tanulási intenzitás (skalár, ~ 0.001 - 1.0 közötti érték)
- ⚬: Hadamard-szorzás (azonos méretű tenzorok elemenkénti szorzata)
- ⊗d: dinamikus tenzor szorzás, amely d dimenziót alakít szorzatösszeggé
- dim(i): az i. réteg dimenziószáma
- *: skalárral történő elemenkénti szorzás
Példa:
A következőkben egy 3 rétegű hálózat példáján keresztül mutatjuk be a hibavisszaterjesztést, amelyben az első (bemeneti) réteg 3 dimenziós (axbxc), a második (rejtett) és a harmadik (kimeneti) réteg pedig 2 dimenziós (dxe illetve fxg).
| 0. réteg | 1. réteg | 2. réteg | |||||||||||
| 0. állapot | 1. súly | 1. szorzat | 1. állapot | 2. súly | 2. szorzat | 2. állapot | Hiba | ||||||
| Hálózat: | X(0) | - | W(1) | - | Z(1) | X(1) | - | W(2) | - | Z(2) | X(2) | - | E |
| Tenzor mérete: | axbxc | dxexaxbxc | dxe | dxe | fxgxdxe | fxg | fxg | fxg | |||||
| Tenzor dimenziószáma: | 3 | 5 | 2 | 2 | 4 | 2 | 2 | 2 | |||||
A hibavisszaterjesztés folyamata (a képletek alatt feltüntettük az egyes tagok tenzor méreteit):
1. A 2. réteg deltája (i = L = 2):
| δ(2) | = | E | ⚬ | a'(X(2)) |
| fxg | fxg | fxg |
2. A 2. réteg súlyváltozása:
| ΔW(2) | = | δ(2) | ⊗0 | X(1) |
| fxgxdxe | fxg | dxe |
3. A 2. réteg új súlytenzora:
| W*(2) | = | W(2) | + | ΔW(2) * r |
| fxgxdxe | fxgxdxe | fxgxdxe |
4. A 2. réteg új erősítési tényezői:
| B*(2) | = | B(2) | + | δ(2) * r |
| fxg | fxg | fxg |
5. A 1. réteg deltája:
| δ(1) | = | ( | δ(2) | ⊗2 | W*(2) | ) | ⚬ | a'(X(1)) |
| dxe | fxg | fxgxdxe | dxe |
6. A 1. réteg súlyváltozása:
| ΔW(1) | = | δ(1) | ⊗0 | X(0) |
| dxexaxbxc | dxe | axbxc |
7. A 1. réteg új súlytenzora:
| W*(1) | = | W(1) | + | ΔW(1) * r |
| dxexaxbxc | dxexaxbxc | dxexaxbxc |
8. A 1. réteg új erősítési tényezői:
| B*(1) | = | B(1) | + | δ(1) * r |
| dxe | dxe | dxe |
3. A konvolúciós neurális háló
A konvolúciós hálóban a rétegek neuronjai a szomszédos rétegbeli párjuk egy kis környezetével van csak összekötve. Ez különösen képfeldolgozási feladatokra alkalmas, mert pont úgy működik mint a kép szűrők. Bonyolultabb feladatokra nem annyira alkalmas, de kicsi az erőforrásigénye.
3.1. A konvolúciós neurális háló elemei
A háló k db. n dimenziós rétegből (layer) és k-1 db. n dimenziós konvolúciós tenzorból áll, amelyek a szomszédos rétegek közötti kapcsolatot jelentik. A rétegek neuronjainak állapotát n dimenziós tenzorok tárolják:
- L1, ..., Lk: a rétegekben található neuronok állapotát tároló, d1(i), d1(i), .... , dn(i) méretű, n dimenziós tenzorok, ahol i = 1, ..., k.
- K1, ..., Kk-1: a rétegek közötti kapcsolatot jelentő konvolúciós (kernel) tezorok, amelyek n dimenziósak és d1(i), d1(i), .... , dn(i) méretűek, ahol i = 1, ..., k-1.
A zárójelbe tett szám a réteg sorszámát jelenti.
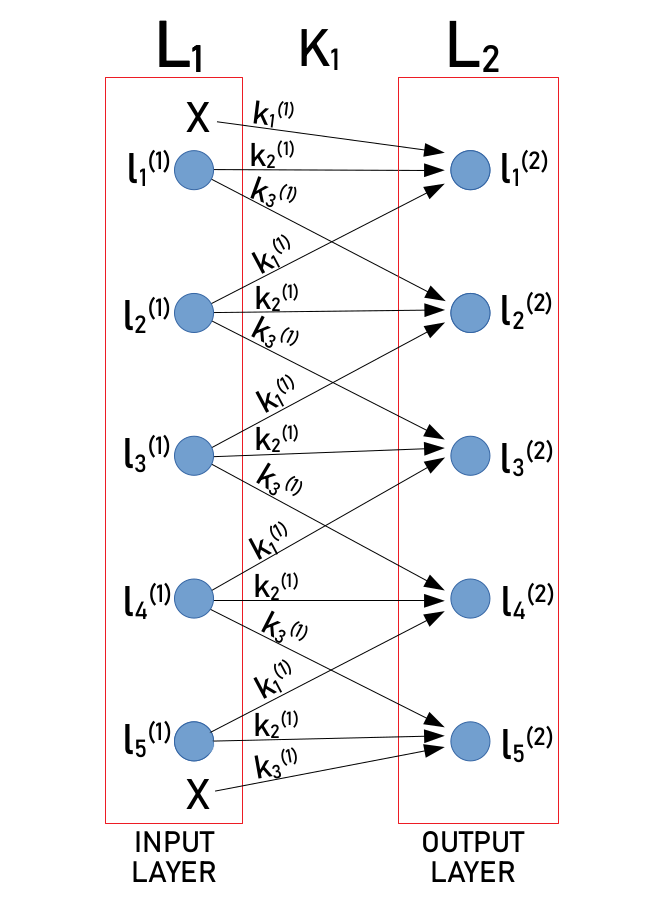
3.2. A konvolúciós háló működése
3.2.1. Előreterjesztés
Normál működés, amikor a bemenet alapján a háló kimenetet képez.
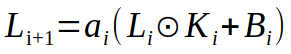
Jelmagyarázat:
- Li: i-dik réteg állapot tenzora
- ai: i-dik réteg aktivációs függvénye
- Ki: i-dik réteg kernel tenzora
- Bi: i-dik réteg erősítési tényező tenzora
- ⊙: tenzor konvolúció
Példa az egy dimenziós esetre, ahol a rétegek állapottenzorai és a kernelek 3 hosszúságú vektorok:
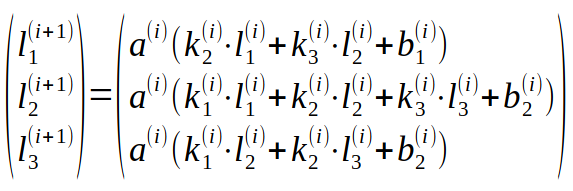
Az ábra az 1. és 2. réteg közötti kapcsolatot mutatja, hogy hogyan kapjuk meg az első réteg értékeiből a második réteg értékeit. A zárójelbe tett szám a réteg sorszámát jelenti.
3.2.2. Hibavisszaterjesztés
A hibavisszaterjesztés folyamata, az elvárt kimenet megtanítása a hálóval.

Jelmagyarázat:
- L: a hálózat rétegszáma
- K(i): az i sorszámú rétegköz konvolúciós kernele
- K*R(i): az i sorszámú rétegköz új, hibavisszaterjesztés utáni konvolúciós kernele 180 fokban elforgatva
- b(i): az i sorszámú rétegköz erősítési tényezője
- b*(i): az i sorszámú rétegköz új erősítési tényezője a hibavisszaterjesztés után
- X(i): az i. réteg állapottenzora
- a'(): aktivációs függvény deriváltja
- E: az utolsó réteg hibatenzora (elvárt kimenet - kimenet különbsége)
- r: tanulási intenzitás (skalár, ~ 0.001 - 1.0 közötti érték)
- ⚬: Hadamard-szorzás (azonos méretű tenzorok elemenkénti szorzata)
- ⊙: konvolúció
- ⊙d: részleges konvolúció, amely d sugarú környezetben konvolvál
- size(T): a T tenzor mérete
- ∑(T): a T tenzot elemenkénti összege
- *: skalárral történő elemenkénti szorzás
4. Gráf alapú háló
4.1. A gráf alapú háló működése
4.1.1. Előreterjesztés
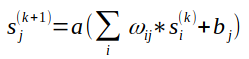
Jelmagyarázat:
- sj(k): A j-dik neuron állapota a k-dik iterációban
- a(): aktivációs függvény
- ωij: az i-dik és j-dik neuron közötti súlytényező
- bj: a j-dik neuron erősítési tényezője
4.1.2. Hibavisszaterjesztés
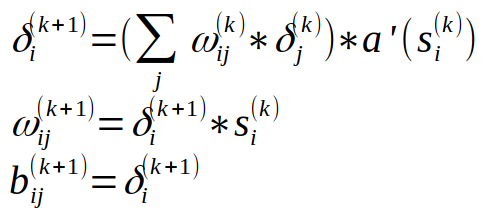
Jelmagyarázat:
- si(k): A i-dik neuron állapota a k-dik iterációban
- a'(): az aktivációs függvény deriváltja
- ωij(k): az i-dik és j-dik neuron közötti súlytényező a k-dik iterációban
- bi(k): az i-dik neuron erősítési tényezője a k-dik iterációban
- δi(k): az i-dik neuron deltája a k-dik iterációban








